










百度搜索引擎工作原理
 分享
分享
 評論
評論
 贊0
贊0
關于百度以及其它搜索引擎的工作原理,其實大家已經討論過很多,但隨著科技的進步、互聯網業的發展,各家搜索引擎都發生著巨大的變化,并且這些變化都是飛快的。我們設計這個章節的目的,除了從官方的角度發出一些聲音、糾正一些之前的誤讀外,還希望通過不斷更新內容,與百度搜索引擎發展保持同步,給各位站長帶來最新的、與百度高相關的信息。本章主要內容分為四個章節,分別為:抓取建庫;檢索排序;外部投票;結果展現。
互聯網信息爆發式增長,如何有效的獲取并利用這些信息是搜索引擎工作中的首要環節。數據抓取系統作為整個搜索系統中的上游,主要負責互聯網信息的搜集、保存、更新環節,它像蜘蛛一樣在網絡間爬來爬去,因此通常會被叫做“spider”。例如我們常用的幾家通用搜索引擎蜘蛛被稱為:Baiduspdier、Googlebot、Sogou Web Spider等。
Spider抓取系統是搜索引擎數據來源的重要保證,如果把web理解為一個有向圖,那么spider的工作過程可以認為是對這個有向圖的遍歷。從一些重要的種子 URL開始,通過頁面上的超鏈接關系,不斷的發現新URL并抓取,盡最大可能抓取到更多的有價值網頁。對于類似百度這樣的大型spider系統,因為每時 每刻都存在網頁被修改、刪除或出現新的超鏈接的可能,因此,還要對spider過去抓取過的頁面保持更新,維護一個URL庫和頁面庫。
下圖為spider抓取系統的基本框架圖,其中包括鏈接存儲系統、鏈接選取系統、dns解析服務系統、抓取調度系統、網頁分析系統、鏈接提取系統、鏈接分析系統、網頁存儲系統。Baiduspider即是通過這種系統的通力合作完成對互聯網頁面的抓取工作。
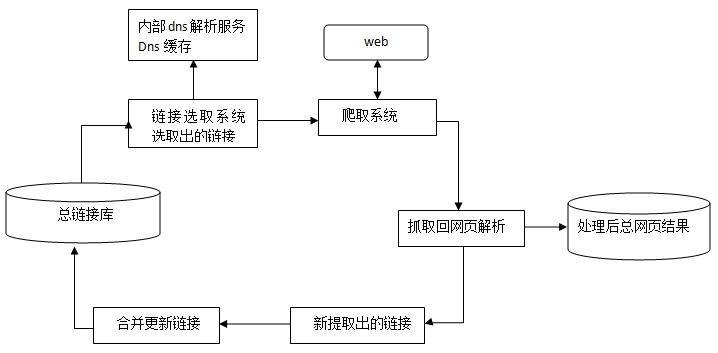
Baiduspider 主要抓取策略類型
上圖看似簡單,但其實Baiduspider在抓取過程中面對的是一個超級復雜的網絡環境,為了使系統可以抓取到盡可能多的有價值資源并保持系統及實際環境中頁面的一致性同時不給網站體驗造成壓力,會設計多種復雜的抓取策略。以下做簡單介紹:
1、抓取友好性
互聯網資源龐大的數量級,這就要求抓取系統盡可能的高效利用帶寬,在有限的硬件和帶寬資源下盡可能多的抓取到有價值資源。這就造成了另一個問題,耗費被抓網站的帶寬造成訪問壓力,如果程度過大將直接影響被抓網站的正常用戶訪問行為。因此,在抓取過程中就要進行一定的抓取壓力控制,達到既不影響網站的正常用戶訪問又能盡量多的抓取到有價值資源的目的。
通常情況下,最基本的是基于ip的壓力控制。這是因為如果基于域名,可能存在一個域名對多個ip(很多大網站)或多個域名對應同一個ip(小網站共享ip)的問題。實際中,往往根據ip及域名的多種條件進行壓力調配控制。同時,站長平臺也推出了壓力反饋工具,站長可以人工調配對自己網站的抓取壓力,這時百度spider將優先按照站長的要求進行抓取壓力控制。
對同一個站點的抓取速度控制一般分為兩類:其一,一段時間內的抓取頻率;其二,一段時間內的抓取流量。同一站點不同的時間抓取速度也會不同,例如夜深人靜月黑風高時候抓取的可能就會快一些,也視具體站點類型而定,主要思想是錯開正常用戶訪問高峰,不斷的調整。對于不同站點,也需要不同的抓取速度。
2、常用抓取返回碼示意
簡單介紹幾種百度支持的返回碼:
1)最常見的404代表“NOT FOUND”,認為網頁已經失效,通常將在庫中刪除,同時短期內如果spider再次發現這條url也不會抓取;
2)503代表“Service Unavailable”,認為網頁臨時不可訪問,通常網站臨時關閉,帶寬有限等會產生這種情況。對于網頁返回503狀態碼,百度spider不會把這條url直接刪除,同時短期內將會反復訪問幾次,如果網頁已恢復,則正常抓取;如果繼續返回503,那么這條url仍會被認為是失效鏈接,從庫中刪除。
3)403代表“Forbidden”,認為網頁目前禁止訪問。如果是新url,spider暫時不抓取,短期內同樣會反復訪問幾次;如果是已收錄url,不會直接刪除,短期內同樣反復訪問幾次。如果網頁正常訪問,則正常抓取;如果仍然禁止訪問,那么這條url也會被認為是失效鏈接,從庫中刪除。
4)301代表是“Moved Permanently”,認為網頁重定向至新url。當遇到站點遷移、域名更換、站點改版的情況時,我們推薦使用301返回碼,同時使用站長平臺網站改版工具,以減少改版對網站流量造成的損失。
3、多種url重定向的識別
互聯網中一部分網頁因為各種各樣的原因存在url重定向狀態,為了對這部分資源正常抓取,就要求spider對url重定向進行識別判斷,同時防止作弊行為。重定向可分為三類:http 30x重定向、meta refresh重定向和js重定向。另外,百度也支持Canonical標簽,在效果上可以認為也是一種間接的重定向。
4、抓取優先級調配
由于互聯網資源規模的巨大以及迅速的變化,對于搜索引擎來說全部抓取到并合理的更新保持一致性幾乎是不可能的事情,因此這就要求抓取系統設計一套合理的抓取優先級調配策略。主要包括:深度優先遍歷策略、寬度優先遍歷策略、pr優先策略、反鏈策略、社會化分享指導策略等等。每個策略各有優劣,在實際情況中往往是多種策略結合使用以達到最優的抓取效果。
5、重復url的過濾
spider在抓取過程中需要判斷一個頁面是否已經抓取過了,如果還沒有抓取再進行抓取網頁的行為并放在已抓取網址集合中。判斷是否已經抓取其中涉及到最核心的是快速查找并對比,同時涉及到url歸一化識別,例如一個url中包含大量無效參數而實際是同一個頁面,這將視為同一個url來對待。
6、暗網數據的獲取
互聯網中存在著大量的搜索引擎暫時無法抓取到的數據,被稱為暗網數據。一方面,很多網站的大量數據是存在于網絡數據庫中,spider難以采用抓取網頁的方式獲得完整內容;另一方面,由于網絡環境、網站本身不符合規范、孤島等等問題,也會造成搜索引擎無法抓取。目前來說,對于暗網數據的獲取主要思路仍然是通過開放平臺采用數據提交的方式來解決,例如“百度站長平臺”“百度開放平臺”等等。
7、抓取反作弊
spider在抓取過程中往往會遇到所謂抓取黑洞或者面臨大量低質量頁面的困擾,這就要求抓取系統中同樣需要設計一套完善的抓取反作弊系統。例如分析url特征、分析頁面大小及內容、分析站點規模對應抓取規模等等。
 猜你喜歡
猜你喜歡
評論(0人參與,0條評論)
發布評論
最新評論