



如何正確識別Baiduspider移動ua
 編輯
編輯
 分享
分享
 評論
評論
 贊0
贊0
如何正確識別Baiduspider移動ua
新版移動ua:
Mozilla/5.0 (Linux;u;Android 4.2.2;zh-cn;) AppleWebKit/534.46 (KHTML,like Gecko) Version/5.1 Mobile Safari/10600.6.3 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
PC ua:
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)
之前通過“+http://www.baidu.com/search/spider.html”進行識別的網站請注意!您需要修改識別方式,新的正確的識別Baiduspider移動ua的方法如下:
1. 通過關鍵詞“Android”或者“Mobile”來進行識別,判斷為移動訪問或者抓取。
2. 通過關鍵詞“Baiduspider/2.0”,判斷為百度爬蟲。
另外需要強調的是,對于robots封禁,如果封禁的agent是Baiduspider,會對PC和移動同時生效。即,無論是PC還是移動Baiduspider,都不會對封禁對象進行抓取。之所以要強調這一點,是發現有些代碼適配站點(同一個url,PC ua打開的時候是PC頁,移動ua打開的時候是移動頁),想通過設置robots的agent封禁達到只讓移動Baiduspider抓取的目的,但由于PC和移動Baiduspider的agent都是Baiduspider,這種方法是非常不可取的。
百度蜘蛛對于站長來說可謂上賓,可是我們曾經遇到站長這樣提問:我們如何判斷瘋狂抓我們網站內容的蜘蛛是不是百度的?其實站長可以通過DNS反查IP的方式判斷某只spider是否來自百度搜索引擎。根據平臺不同驗證方法不同,如linux/windows/os三種平臺下的驗證方法分別如下:
1、在linux平臺下,您可以使用host ip命令反解ip來判斷是否來自Baiduspider的抓取。Baiduspider的hostname以 *.baidu.com 或 *.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即為冒充。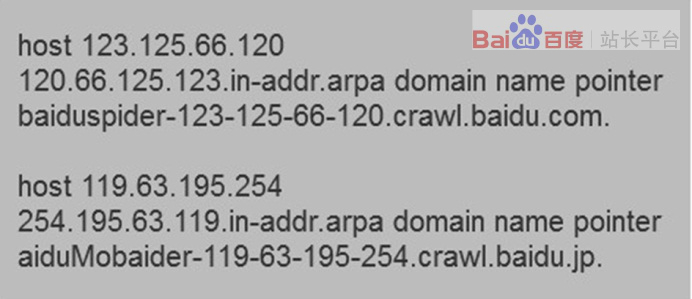
2、在windows平臺或者IBM OS/2平臺下,您可以使用nslookup ip命令反解ip來 判斷是否來自Baiduspider的抓取。打開命令處理器 輸入nslookup xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 來判斷是否來自Baiduspider的抓取,Baiduspider的hostname以*.baidu.com 或*.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即為冒充。
3、 在mac os平臺下,您可以使用dig 命令反解ip來 判斷是否來自Baiduspider的抓取。打開命令處理器 輸入dig xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 來判斷是否來自Baiduspider的抓取,Baiduspider的hostname以 *.baidu.com 或*.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即為冒充。
即便很多站長知道了如何判斷百度蜘蛛,仍然會不斷地問“百度蜘蛛IP是多少”。我們理解站長的意思,是想將百度蜘蛛所在IP加入白名單,只準白名單下IP對網站進行抓取,避免被采集等行為。
但我們不建議站長這樣做。雖然百度蜘蛛的確有一個IP池,真實IP在這個IP池內切換,但是我們無法保證這個IP池整體不會發生變化。所以,我們建議站長勤看日志,發現惡意蜘蛛后放入黑名單,以保證百度的正常抓取。
同時,我們再次強調,通過IP來分辨百度蜘蛛的屬性是非常可笑的事情,所謂的“沙盒蜘蛛”“降權蜘蛛”等等是從來都不存在的。
robots是站點與spider溝通的重要渠道,站點通過robots文件聲明該網站中不想被搜索引擎收錄的部分或者指定搜索引擎只收錄特定的部分。請注意,僅當您的網站包含不希望被搜索引擎收錄的內容時,才需要使用robots.txt文件。如果您希望搜索引擎收錄網站上所有內容,請勿建立robots.txt文件。
robots文件往往放置于根目錄下,包含一條或更多的記錄,這些記錄通過空行分開(以CR,CR/NL, or NL作為結束符),每一條記錄的格式如下所示:
"<field>:<optional space><value><optionalspace>"
在該文件中可以使用#進行注解,具體使用方法和UNIX中的慣例一樣。該文件中的記錄通常以一行或多行User-agent開始,后面加上若干Disallow和Allow行,詳細情況如下:
User-agent:該項的值用于描述搜索引擎robot的名字。在"robots.txt"文件中,如果有多條User-agent記錄說明有多個robot會受到"robots.txt"的限制,對該文件來說,至少要有一條User-agent記錄。如果該項的值設為*,則對任何robot均有效,在"robots.txt"文件中,"User-agent:*"這樣的記錄只能有一條。如果在"robots.txt"文件中,加入"User-agent:SomeBot"和若干Disallow、Allow行,那么名為"SomeBot"只受到"User-agent:SomeBot"后面的 Disallow和Allow行的限制。
Disallow:該項的值用于描述不希望被訪問的一組URL,這個值可以是一條完整的路徑,也可以是路徑的非空前綴,以Disallow項的值開頭的URL不會被 robot訪問。例如"Disallow:/help"禁止robot訪問/help.html、/helpabc.html、/help/index.html,而"Disallow:/help/"則允許robot訪問/help.html、/helpabc.html,不能訪問/help/index.html。"Disallow:"說明允許robot訪問該網站的所有url,在"/robots.txt"文件中,至少要有一條Disallow記錄。如果"/robots.txt"不存在或者為空文件,則對于所有的搜索引擎robot,該網站都是開放的。
Allow:該項的值用于描述希望被訪問的一組URL,與Disallow項相似,這個值可以是一條完整的路徑,也可以是路徑的前綴,以Allow項的值開頭的URL 是允許robot訪問的。例如"Allow:/hibaidu"允許robot訪問/hibaidu.htm、/hibaiducom.html、/hibaidu/com.html。一個網站的所有URL默認是Allow的,所以Allow通常與Disallow搭配使用,實現允許訪問一部分網頁同時禁止訪問其它所有URL的功能。
使用"*"and"$":Baiduspider支持使用通配符"*"和"$"來模糊匹配url。
"*" 匹配0或多個任意字符
"$" 匹配行結束符。
最后需要說明的是:百度會嚴格遵守robots的相關協議,請注意區分您不想被抓取或收錄的目錄的大小寫,百度會對robots中所寫的文件和您不想被抓取和收錄的目錄做精確匹配,否則robots協議無法生效。
上面說了那么多理論,有沒有簡單對照表格告訴我,怎樣的需求場景下應該怎樣撰寫robots文件?有的: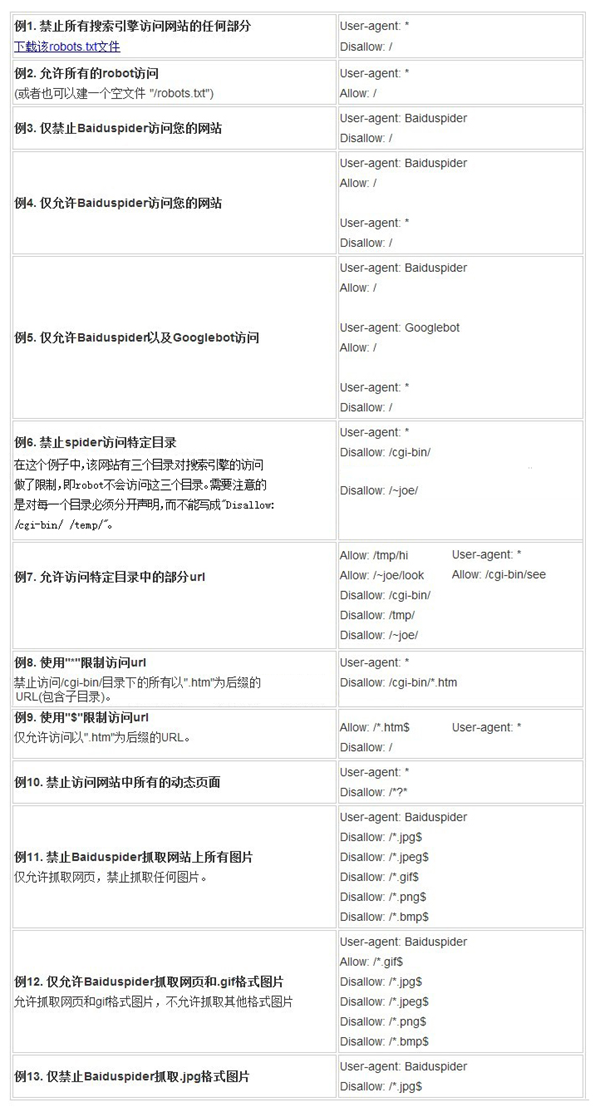
除robots外其它禁止百度收錄的方法Meta robots標簽是頁面head部分標簽的一種,也是一種用于禁止搜索引擎索引頁面內容的指令。目前百度僅支持nofollow和noarchive
nofollow:禁止搜索引擎跟蹤本頁面上的鏈接
如果您不想搜索引擎追蹤此網頁上的鏈接,且不傳遞鏈接的權重,請將此元標記置入網頁的<HEAD> 部分:<meta name="robots" content="nofollow">
如果您不想百度追蹤某一條特定鏈接,百度還支持更精確的控制,請將此標記直接寫在某條鏈接上:<a href="signin.php" rel="nofollow">signin</a>
要允許其他搜索引擎跟蹤,但僅防止百度跟蹤您網頁的鏈接,請將此元標記置入網頁的<HEAD> 部分:<meta name="Baiduspider" content="nofollow">
noarchive:禁止搜索引擎在搜索結果中顯示網頁快照
要防止所有搜索引擎顯示您網站的快照,請將此元標記置入網頁的<HEAD>部分:<meta name="robots" content="noarchive">
要允許其他搜索引擎顯示快照,但僅防止百度顯示,請使用以下標記:<meta name="Baiduspider" content="noarchive">
注:此標記只是禁止百度顯示該網頁的快照,百度會繼續為網頁建索引,并在搜索結果中顯示網頁摘要。
對于百度搜索引擎來說,蜘蛛黑洞特指網站通過極低的成本制造出大量參數過多、內容類同但url不同的動態URL ,就像一個無限循環的“黑洞“,將spider困住。spider浪費了大量資源抓取的卻是無效網頁。
如很多網站都有篩選功能,通過篩選功能產生的網頁經常會被搜索引擎大量抓取,而這其中很大一部分是檢索價值低質的頁面。如“500-1000之間價格的租房”,首先網站(包括現實中)上基本沒有相關資源,其次站內用戶和搜索引擎用戶都沒有這種檢索習慣。這種網頁被搜索引擎大量抓取,只能是占用網站寶貴的抓取配額,那么該如何避免這種情況呢?
我們以北京美團網為例,看看美團網是如何利用robots巧妙避免這種蜘蛛黑洞的:
對于普通的篩選結果頁,使用了靜態鏈接,如:
http://bj.meituan.com/category/zizhucan/weigongcun
同樣是條件篩選結果頁,當用戶選擇不同排序條件后,會生成帶有不同參數的動態鏈接,而且即使是同一種排序條件(如:都是按銷量降序排列),生成的參數也都是不同的。如:http://bj.meituan.com/category/zizhucan/weigongcun/hot?mtt=1.index%2Fpoi.0.0.i1afqhekhttp://bj.meituan.com/category/zizhucan/weigongcun/hot?mtt=1.index%2Fpoi.0.0.i1afqi5c
對于美團網來說,只讓搜索引擎抓取篩選結果頁就可以了,而各種帶參數的結果排序頁面則通過robots規則拒絕提供給搜索引擎。在robots.txt的文件用法中有這樣一條規則:Disallow: /*?* ,即禁止搜索引擎訪問網站中所有的動態頁面。美團網恰是通過這種方式,對spider優先展示高質量頁面、屏蔽了低質量頁面,為spider提供了更友好的網站結構,避免了黑洞的形成。
禁止百度圖片搜索收錄某些圖片的方法目前百度圖片搜索也使用了與百度網頁搜索相同的spider,如果想禁止Baiduspider抓取網站上所有圖片、禁止或允許Baiduspider抓取網站上的某種特定格式的圖片文件可以通過設置robots實現:
禁止Baiduspider抓取網站上所有圖片 | User-agent: Baiduspider |
僅允許Baiduspider抓取網頁和.gif格式圖片 | User-agent: Baiduspider |
僅禁止Baiduspider抓取.jpg格式圖片 | User-agent: Baiduspider |
Html狀態碼也是網站與spider進行交流的渠道之一,會告訴spider網頁目前的狀態,spider再來決定下一步該怎么做——抓or不抓or下次再來看看。對于200狀態碼大家已經很熟了,那么我們來介紹幾種常見的失效網頁使用的狀態碼:
【404】404返回碼的含義是“NOT FOUND”,百度會認為網頁已經失效,那么通常會從搜索結果中刪除,并且短期內spider再次發現這條url也不會抓取。
【503】503返回碼的含義是“Service Unavailable”,百度會認為該網頁臨時不可訪問,通常網站臨時關閉,帶寬有限等會產生這種情況。對于網頁返回503,百度spider不會把這條url直接刪除,短期內會再訪問。屆時如果網頁已恢復,則正常抓取;如果繼續返回503,短期內還會反復訪問幾次。但是如果網頁長期返回503,那么這個url仍會被百度認為是失效鏈接,從搜索結果中刪除。
【301】301返回碼的含義是“Moved Permanently”,百度會認為網頁當前跳轉至新url。當遇到站點遷移,域名更換、站點改版的情況時,推薦使用301返回碼,盡量減少改版帶來的流量損失。雖然百度spider現在對301跳轉的響應周期較長,但我們還是推薦大家這么做。
一些網站把未建好的頁面放到線上,并且這些頁面在被百度抓取的時候返回碼是404,于是頁面被百度抓取后會被當成死鏈直接刪除。但是這個頁面在第二天或者過幾天就會建好,并上線到網站內展現出來,但是由于之前已經被百度當做死鏈刪除,所以要再次等這些鏈接被發現,然后抓取才能展現,這樣的操作最終會導致一些頁面在一段時間內不會在百度出現。比如某個大型門戶網站爆出大量新聞時效性很強的專題未被百度及時收錄的問題,經檢查驗證后發現就是因為頁面未建成就放置在線上,并返回404狀態碼,被百度當成死鏈刪除,造成收錄和流量損失。
對于這樣的問題,建議網站使用503返回碼,這樣百度的抓取器接到503返回碼后,會在隔一段時間再去訪問這個地址,在您的頁面建好上線后,就又能被重新抓取,保證頁面及時被抓取和索引,避免未建好的內容設為404后帶來不必要的收錄和流量損失。
其它建議和總結:
1、如果百度spider對您的站點抓取壓力過大,請盡量不要使用404,同樣建議返回503。這樣百度spider會過段時間再來嘗試抓取這個鏈接,如果那個時間站點空閑,那它就會被成功抓取了
2、如果站點臨時關閉或者頁面暫未建好上線,當網頁不能打開時以及沒有建好時,不要立即返回404,建議使用503狀態。503可以告知百度spider該頁面臨時不可訪問,請過段時間再重試。
在百度site站點時,遇到“連通率為0”說明Baiduspider在訪問站點時發現了問題,該問題非常嚴重,如果Baiduspider持續一天時間無法訪問有可能給站點帶來災難性的損失。
一、何謂連通率
既然為率,那么就是一個統計相關概念。我們不妨可以這樣理解一個網站的連通率:百度蜘蛛在抓取網站頁面的時候計算的一個概率,比如它抓取某網站中的N個頁面,這N個頁面都能打開并被蜘蛛成功抓取,這樣的連通率就是N/N=100%,反之蜘蛛抓取N個頁面有M個頁面能成功抓取,連通率就是M/N
這里先說明幾個常識:
1、不是網站被某算法懲罰而導致連通率為0,也不是網站流量下降而導致連通率數值很低;
2、連通率代表著百度蜘蛛獲取網站數據的情況,如果連通率數值很低或為0,那么可能連維持網站的正常收錄等都成問題;
3、假如網站被判定連通不了,那么如果讓一個連通不了的站點在百度中獲取排名,就會大大影響搜索用戶的體驗,于是百度就會采取對該站點有效引流的索引清除操作,一些站長就會發現自己的網站索引量突然大幅度下降,甚至索引被短暫清0了,接著就是網站百度搜索流量大幅度下降,這種突發性的事件又會造成站長們的揣測,以為自己的網站被百度懲罰了,其實站長們先應該注意的是站點的連通情況。
二、提取核心詞
上述概念中,我們需要注意的幾個詞有:”百度蜘蛛”; ”在抓取”; ”N個頁面”; ”M個頁面”; ”都能打開并被成功抓取”。
三、連通率很低或為0時
我們抓住上述5個提取出的核心詞進行分析。
(一)百度蜘蛛
1、謹防百度蜘蛛訪問被操控或禁止
(1)由于百度蜘蛛的抓取量等原因對一些服務器造成壓力,而這些網絡商或網站運營方從某利益角度考慮,無意或有意的屏蔽百度蜘蛛,導致部分或全部百度蜘蛛ip獲取不到網站數據;
(2)一些網站運營方或網絡商對蜘蛛進行區別對待,比如國外蜘蛛ip、山東蜘蛛ip、北京蜘蛛ip等返回不同的數據,移花接木的手段層出不窮,而這個過程很可能造成百度蜘蛛的異常行為或異常狀態返回;
所以我們首先要確保百度蜘蛛的訪問有沒有被操控或禁止。
2、預防措施
(1)完善聯系方式獲得百度站長工具消息提醒
雖然一些網站異常情況會收到百度站長工具消息提醒,然而我想告訴大家不是所有自己站點異常都可以寄希望于消息提醒的,自己心里要知道連發郵件都可能出現收不到的情況,更何況各種復雜的異常情況,因此不要出問題了只會問“為什么站長工具沒有給我發消息”。
(2)利用抓取異常和抓取頻次工具觀察抓取情況
↓抓取異常工具的網址異常情況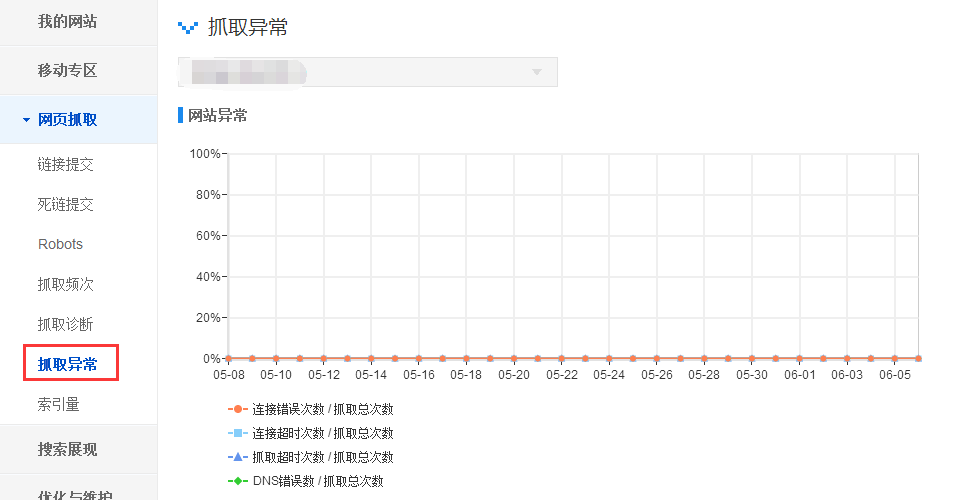
↓抓取頻次工具的抓取統計情況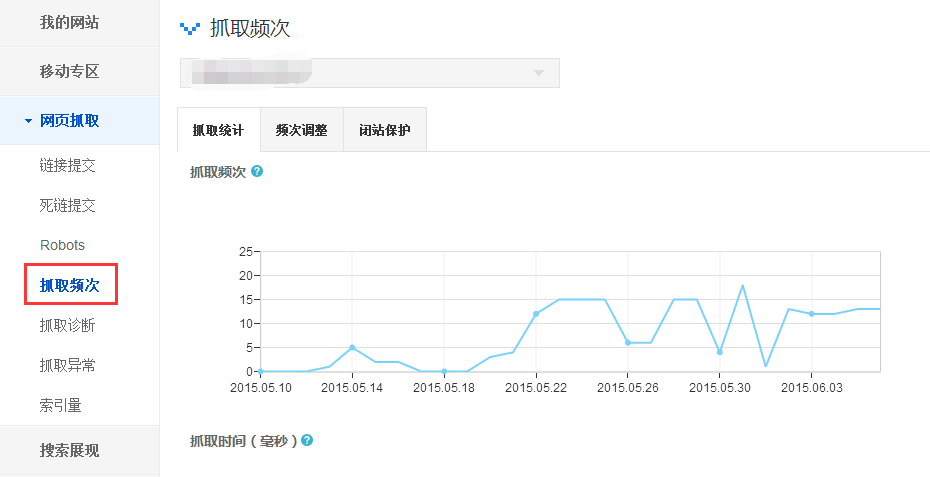
↓每個工具頁面的右側下方都有使用說明,如下
(3)抓取診斷工具是重中之重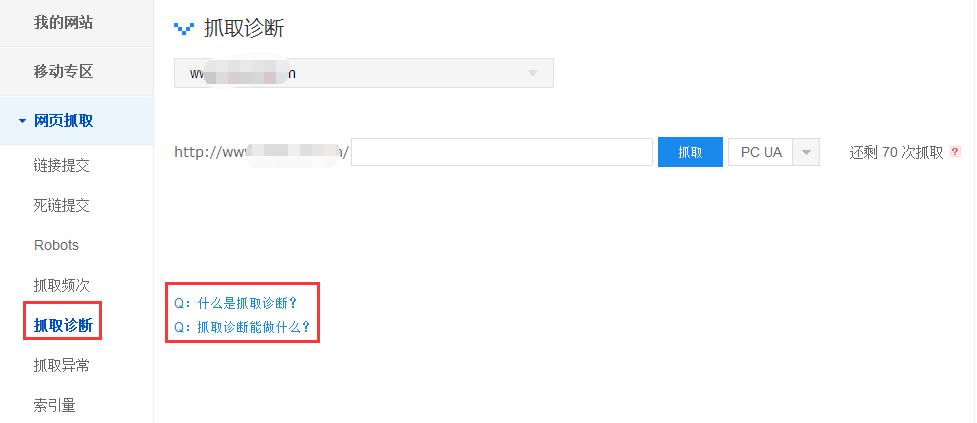
為了保證網站對百度蜘蛛的穩定訪問性能,日常我們需要養成定期抓取診斷的習慣,另外抓取診斷不是說光看看狀態是否“抓取成功”就行了。有下面幾步進行:
第一步:下拉選擇分”pc”、 ”移動”進行抓取,”pc”意味著一般意義上的電腦端訪問診斷,”移動”則是如手機、平板等移動設備端訪問診斷;
第二步:網站主要的引流頁,如首頁、詳情頁、內容頁、專題頁等都要進行抓取,另外可以重點幾個時間段(比如網站高峰時間段)每天定期進行測試;
第三步:抓取失敗了,點擊”抓取失敗”查看提示信息,如果自己沒有技術能力解決問題,可以跟空間商進行溝通,然后向工具提交報錯;

第四步:抓取成功后,也不能說就萬事大吉了,還要點擊”抓取成功”進去注意:提交網址、抓取網址、抓取UA、網站ip、下載時長、頭部信息(服務器返回狀態碼、gzip等相關信息)、網頁源碼是否都正常。

特別說明:有很多站長就光注意抓取成功,卻不知網站ip可能并非自己的實際ip,被網絡商搞到哪里去了都不知道,還可能每隔一段時間都變。當發現ip有問題,及時跟網絡商溝通,并在網站ip旁點擊“報錯”按鈕,百度會更新網站ip,但是切記不要ip變化頻繁。此外當然還可能出現實際抓取網址、頭部信息、網頁源碼等都不是自己本來設置的。
(二)在抓取
這是反映百度蜘蛛在抓取時的狀態,百度的工具顯示的數值肯定都是抓取后計算出來的數據,因此任何工具的連通率數據必定存在延遲性,另外這個計算過程也存在一定可能的錯誤,所以我們看到任何工具中關于連通率的數據,不要說“我網站用抓取診斷等工具檢查訪問情況都好好的,為什么連通率還是0”,因此除了上述建議的多抓取診斷測試外,自己可以加些監控網站連接狀態的措施,筆者本人就曾經接收了不少關于網站連接不通的提醒。這時我會及時跟網絡商溝通,然后及時用抓取診斷檢查蜘蛛的情況。
(三)N個頁面與M個頁面
這N、M個頁面,可能百度蜘蛛很湊巧就趕上高峰的時候或者一些假死頁面(執行時間較長,超過蜘蛛的耐心),那么M這個數值就會很低,統計概率的東西大家都懂的,那么這時網站的連通率依舊很低或為0。因此若連通率為0,我們還可以知道自己應該注意查看訪問日志,及時清理死鏈,或者并發連接數增大,或者增加內存等等。
 猜你喜歡
猜你喜歡